课程地址: https://www.coursera.org/learn/machine-learning/home/welcome
第四周 神经网络-模型
4.1 模型
4.1.1 基本元素
- 激活函数(activation function) , $g(z)$ , $a_i^{(j)}$第$j$层的第$i$个神经元
- 偏置神经元(bias unit)
- 权重(Weight)
- 输入层 Input Layer
- 结果层 Output Layer
- 隐藏层 Hidden Layer
- $a_i^{(j)}$ 表示在$j$层的第$i$ 个单元
- $\Theta^j$ 权重矩阵控制$j$到$j+1$层各个神经元的权重,如果$j$层有$S_j$个神经元,$j+1$层有$S_{j+1}$个神经元,那么$\Theta^{(j)}$是$S_{j+1} \times S_j +1 $ 矩阵.
4.1.2 计算公式
$ [x_1 x_2 x_3] \rightarrow [a_1^2 a_2^2 a_3^2 …. ] \rightarrow h_\theta(x) $
计算 $ a_1^{(2)} = g(\Theta_{10}^{(1)}x_0 + \Theta_{11}^{(1)}x_1 + \Theta_{12}^{(1)}x_2 + \Theta_{13}^{(1)}x_3) \\ a_2^{(2)} = g(\Theta_{20}^{(1)}x_0 + \Theta_{21}^{(1)}x_1 + \Theta_{22}^{(1)}x_2 + \Theta_{23}^{(1)}x_3) \\ a_3^{(2)} = g(\Theta_{30}^{(1)}x_0 + \Theta_{31}^{(1)}x_1 + \Theta_{32}^{(1)}x_2 + \Theta_{33}^{(1)}x_3) \\ h_\Theta(x) = a_1^{(3)} = g(\Theta_{10}^{(2)}a_0^{(2)} + \Theta_{11}^{(2)}a_1^{(2)} + \Theta_{12}^{(2)}a_2^{(2)} + \Theta_{13}^{(2)}a_3^{(2)}) \\ $
向量化:
$ z^{(j+1)} = \Theta^{(j)}a^{(j)} $
$a^{(j)} = g(z^{(j)})$
$h_{\Theta}(x) =a^{(j+1)} = g(z^{(j+1)})$
预测结果为向量:
$ y^{(i)} = \begin{bmatrix} h_{\Theta}(x)1 \\ h{\Theta}(x)_2 \\ …. \\ \end{bmatrix} $
Octive Matlab Tips:
[m,n] = max(A,[],2)可以查找矩阵每行的最大值的位置.
第五周 神经网络-训练
通过正向传播算法和反向传播算法来进行神经网络的训练
5.1 代价函数$j$
来看看这个复杂到爆的代价函数.
$L$ 网络的总层数
$s_l$ 第 $l$层的单元数量,不包含偏置单元
$K$ 输出单元数量,即要分出的类别的数量
$J(\Theta) = - \frac{1}{m} \sum_{i=1}^m \sum_{k=1}^K [y^{(i)}k \log ((h\Theta(x^{(i)}))k) + (1 - y^{(i)}k)\log(1 - (h\Theta(x^{(i)}))k)] + \frac{\lambda}{2m}\sum{l=1}^{L-1}\sum{i=1}^{s_l}\sum_{j=1}^{s_{l+1}}(\Theta_{j,i}^{(l)})^2 $
5.2 反向传播算法
计算步骤,训练集$(x^{(t)},y^{(t)})$
- 执行正向传播算法计算出$h_{\Theta}(x)$
- 对于第$l$层的每个节点$j$.计算误差$\delta_j^{(l)}$.这个值表示本层输出与正确值的误差
5.2.1 初始化
我们的训练集 为 ${(x^{(1)},y^{(1)})\ … \ (x^{(m)},y^{(m)}}$ 将权重矩阵$\Delta^l$初始化为0矩阵.
5.2.2 计算正向传播
注意计算每一层的时候 都要加上一个 $a_0^{(l)} = 0$.
对于训练样本 $t = 0 … m $
设置 $a^{(1)} = x^{(t)}$
计算正向传播每层的 $a{(l)}$的值,$l = 2,3,4 \ …\ L$
需要提供 $J(\Theta)$ 和他的偏导数$\frac{\partial}{\partial\Theta^{(l)}_{i,j}}J(\Theta)$ 来运行梯度下降或其他高级算法
$ z^{(l)} = \Theta^{(l-1)}a^{(l-1)} \\ a^{(l)} = g(z^{(l)}) \\ a^{(L)} = h_{\Theta}(x) = g(z^L) $
5.2.3 使用$y^t$计算
最后一层.使用样本的正确结果减去通过神经元激活函数算出的值获取我们计算的总偏差. 通过公式我们可以反向推算出上一层的偏差.依次推到第一层.
$\delta^L = a^L - y^{(t)}$
5.2.4 计算上一层的偏差值 $\delta^{(L-1)},\delta ^{(L-2)},\ … \ \delta ^2$
每个权重都是下一层的误差乘激活函数的 偏导数$\delta_j^{(l)}=\frac{\partial}{\partial z_j^{(l)}}cost(t)$,对数据进行一些微调.
另外不用计算第一层, $l = 1 … L-1 $.
$ \delta^{(l)} = (\Theta^{(l)})^T\delta^{(l+1)} \cdot g’(z^{(l)}) $
将偏导数带入:
$\delta^{(l)} = ((\Theta^{(l)})^T\delta^{(l+1)}) \cdot a^{(l)} \cdot (1-a^{(l)})$
5.2.5 更新权重矩阵
公式:
$\Delta^{(l)}{i,j} := \Delta^{(l)}{i,j} + a_j^{l}\delta^{l+1}_{i,j}$
对应的向量公式:
$\Delta^{(l)} := \Delta^{(l)} + \delta^{(i+1)}(a^{(l)})^T$
然后计算新的$\Delta$矩阵
$j\ne0 $时
$ D^{(l)}{ij} := \frac{1}{m}(\Delta{i,j}^{(l)} + \lambda\Theta_{i,j}^{(l)}) $
$j=0 $时去掉正规化相关内容
$ D^{(l)}{ij} := \frac{1}{m}\Delta{i,j}^{(l)} $
5.2.6 参数展开
-A(:)会将矩阵展开到一个长矢量
reshape(a(startElement,endElement),row,column)用于从矢量构建矩阵fminuncinitTherta都是使用长矢量传递
5.2.7 梯度检查
在确认算法正确,进行正式的学习时一定要关闭这个检查不然会慢的要死
用于检验反向传播算法是否正确 .
对于我们的代价函数$j$可以使用这种原始的方法来求导
$ \frac{\partial}{\partial\Theta}J(\Theta) \approx \frac{J(\Theta + \epsilon) - J(\Theta - \epsilon)}{2\epsilon} $
多个$\Theta$值的矩阵
$ \frac{\partial}{\partial\Theta}J(\Theta) \approx \frac{J(\Theta_1,\Theta_2,\ … \ \Theta_j + \epsilon\ …\ \Theta_n) - J(\Theta_1,\Theta_2,\ … \ \Theta_j - \epsilon\ …\ \Theta_n)}{2\epsilon} $
通常设置 $\epsilon = 10^{-4}$ 太小会引起一些数值问题
epsilon = 1e-4;
for i = 1:n,
thetaPlus = theta;
thetaPlus(i) += epsilon;
thetaMinus = theta;
thetaMinus(i) -= epsilon;
gradApprox(i) = (J(thetaPlus) - J(thetaMinus))/(2*epsilon)
end;
运行算法后 检查 gradApprox ≈ deltaVector 来确保你算法的实现没有BUG.
5.2.8 随机化初始化
如果将$\Theta$全部初始化为0或者同样的数,则每个神经元执行同样的函数.网络将具有单一的特性,被称为对称现象,.因此需要进行随机初始化 (真乃玄学).
生成的$\Theta$在 - INIT_SPSILION 到INIT_SPSILION之间.
Theta1 = rand(10,11) * (2 * INIT_EPSILON) - INIT_EPSILON;
Theta2 = rand(10,11) * (2 * INIT_EPSILON) - INIT_EPSILON;
Theta3 = rand(1,11) * (2 * INIT_EPSILON) - INIT_EPSILON;
rand(10,11) 生成一个矩阵,元素值在 0 - 1 之间 函数
func1(arg1 ... arg2)中的...仅用于换行
5.2.9 总结
- 网络结构选择
- 输入层(input layer)神经元数量即为我们的特征的数量
n - 输出层(output layer) 单元神经元数量即为我们要分出的全部类别的数量
- 如果分类数量为$k$则输出层输出为 $y(k,1)$的向量,元素为 $0$和$1$,需要另外进行转换
- 隐藏层(hidden layer)的选择
- 1个隐藏层的网络
- 多于一层,每层有相同的神经元数量
- 层肯定是越多越好,但是计算代价也会变很高
- 每层的单元数量通常是要比输出层数量多
- 输入层(input layer)神经元数量即为我们的特征的数量
- 训练神经网络
-
- 使用随机数初始化节点的权重
- 2.实现前向传播算法
- 3.实现代价函数
- 4.实现反向传播计算微分值
- 5.使用梯度检查算法确认反向传播计算正确,然后关闭梯度检查
- 6.使用梯度递减或者内部的优化功能获取代价最小化的权重矩阵值
- 正向传播可以使用for循环计算每个训练数据
-
for i = 1:m,
Perform forward propagation and backpropagation using example (x(i),y(i))
(Get activations a(l) and delta terms d(l) for l = 2,...,L
Matlab&Octave 函数
第六周 机器学习系统设计
6.1 评估学习算法
- 通常可以提高预测准确性的方法
- 获取更多的训练集 - 修复高方差
- 少选择一些特征量 - 修复高方差
- 尝试更多的特征量 - 修复高偏差
- 尝试多项式特征值 - 修复高偏差
- 减少$\lambda$ - 修改高偏差
- 增加$\lambda$ - 修复高方差
- 评估预测函数
- 将训练集随机分为
70%的训练集和30%的测试集. - 将训练集得到的$\theta$带入测试集,计算误差值.
- 将训练集随机分为
- 模型选择,$d$ 表示多项式的维数,应用到交叉验证集来确定何种多项式更合适.
- 训练集划分
- 交叉验证集 CV 20% -
- 测试集 20%
- 训练集 60%
- 使用三个训练集计算三个不同的误差
- 对于多个多项式使用训练集来找到最优化的$\Theta$
- 使用交叉训练集找到最小误差的$d$
- 用测试集计算泛化误差
- 训练集划分
6.2 偏差和方差
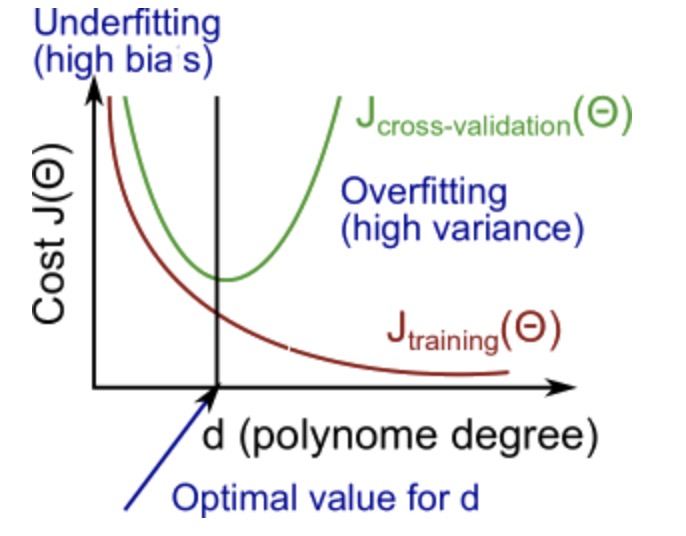
高偏差(欠拟合,预测函数多项式过低)
- $J_{train}(\Theta)$ 高
- $J_{cv}(\Theta)$ 高 并与$J_{train}(\Theta)$相似
高方差(过拟合,预测函数多项式过高)
- $J_{train}(\Theta)$ 低
- $J_{cv}(\Theta)$ 高 并远高于$J_{train}(\Theta)$
与正规化的关系
训练集和CV集不加入正规化选项
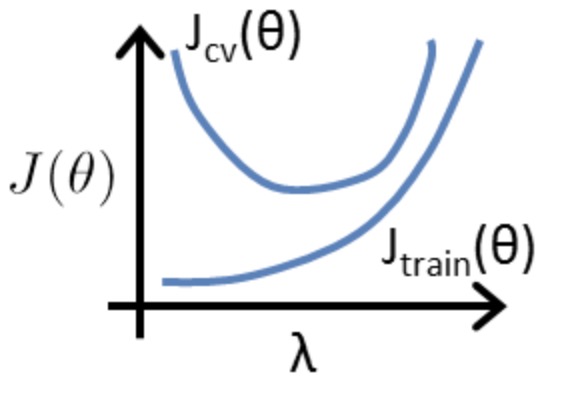
- $\lambda$ 过小可能是过拟合状态
- $\lambda$则是高偏差的不拟合状态
学习曲线
X轴训练量,Y误差

高偏差情况.$J_{cv}$和$J_{train}$ 快速收敛到一起,并将误差保持到较高位置. 此时是高偏差情况,需要更复杂的预测函数.增加训练集没有效果

高方差情况,$J_{cv}$和$J_{train}$ 之间有较大差距,随着训练集的增大差距缩小 此时可能需要更多的训练集.
神经网络的偏差和方差
- 通常大型的网络结构性能更好
- 增加网络层数可以改善高偏差问题
- 层数越多越容易过拟合-通过正规化增加$\lambda$来改善
- 通过对比不同隐藏层的学习曲线进行结构选择,可以先从一层网络开始尝试
- 模型影响
- 低阶模型,高偏差,低方差
- 高阶模型,低偏差,高方差
- 选择复杂度居中的模型
6.3 误差分析
应用机器学习的方法
- 用你能最快实现的简单的算法来实现并在你的验证集测试它.
- 画出学习曲线来决定更多数据或者更多特征量能提供帮助
- 误差分析,手动的分析验证集中的误差,尝试找到规律
- 建立评估算法的数值系统来帮助自己做决定.预测误差率
Skewed Classes 偏斜的分类误差度量
在偏斜的分类中,直接使用预测误差率会无法进行评估.比如:一个二元分类,0 的训练集 占了绝大多数.直接预测 0 会得到很小的误差率.因此单纯使用误差率是无法判断对算法的 修改是模型表现更好.
此类情况使用准确率($P$)召回率($R$)来评估
$Accuracy = \frac{True\ positives + False\ positives }{#total examples} = \frac{\mbox{预测和真实均为阳性} + \mbox{预测和真实均为阴性} }{\mbox{样本总量}}$
$Precision = \frac{True\ positives}{#predicted \ positive} = \frac{\mbox{预测和真实均为阳性}}{\mbox{预测的阳性}}$
$Recall = \frac{True\ positives}{#actual \ positive} = \frac{\mbox{预测和真实均为阳性}}{\mbox{真实的阳性}}$
高准确率和高召回率说明算法运行良好,使用精度和召回进行度量避免算法在偏斜的训练集中被欺骗.
召回率和准确率的平衡
修改分类算法预测的临界值,(默认0.5)
- 临界值,越大则$P$ 越大,
- 临界值越小则$R$ 越大
F公式,通过召回率和准确率计算F值,选择F值较大的算法
$F_1= 2\frac{PR}{P+R}$
F值取值在 0 - 1之间,越大越好.
在交叉验证集上进行测试
6.4 训练数据
- 在确保特征值有足够的信息进行预测的情况下,增大数据集可以提高算法性能
- 在有较多特征值(神经网络有大量隐藏层)的情况下使用大量训练集不容易过拟合
「真诚赞赏,手留余香」
 我的乐与怒
我的乐与怒
真诚赞赏,手留余香
使用微信扫描二维码完成支付
